Warum Word bei der Konvertierung von Webseiten zu DOCX 'Unlesbarer Inhalt' anzeigt
Einleitung
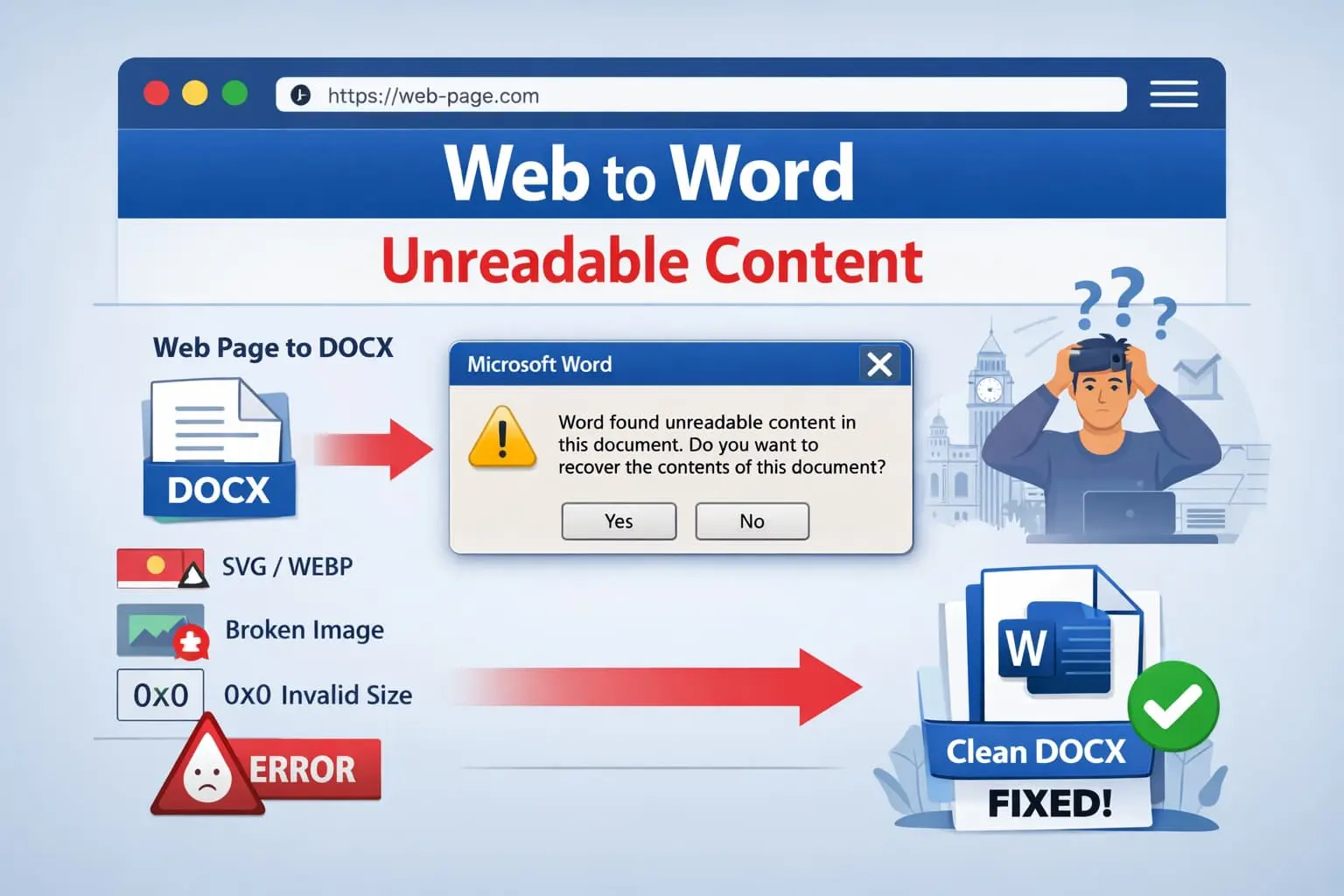
Wenn Sie jemals eine Webseite nach Word konvertiert und von dieser Meldung begrüßt wurden:
„Word hat nicht lesbaren Inhalt in diesem Dokument gefunden. Möchten Sie den Inhalt wiederherstellen?"
sind Sie nicht allein.
Dieses Problem betrifft:
Der frustrierende Teil? Das Dokument sieht in Google Docs gut aus — aber Microsoft Word lehnt es ab.
Dieser Artikel erklärt den wahren technischen Grund hinter der DOCX-Unlesbarkeit, warum die meisten Konverter scheitern und wie Sie das Problem auf Ingenieur-Niveau beheben — nicht mit Hacks.
Was „Unlesbarer Inhalt" in Word tatsächlich bedeutet
Microsoft Word beschwert sich nicht über Ihren Text.
Es teilt Ihnen mit, dass die OpenXML-Struktur der DOCX-Datei ungültig ist.
Eine .docx-Datei ist:
Wenn ein einziges Element die Spezifikation verletzt, markiert Word das gesamte Dokument als beschädigt.
Warum Web-zu-Word-Konvertierung besonders fragil ist
Webseiten wurden nie dafür konzipiert, Word-Dokumente zu werden.
Sie enthalten:
Word hingegen erwartet:
Diese Diskrepanz ist der Punkt, an dem alles zusammenbricht.
Die #1 Hauptursache: Bilder, nicht Text
In über 90% der realen Fälle sind Bilder der Grund, warum Word unlesbaren Inhalt meldet.
Häufige fatale Probleme umfassen:
1. Nicht übereinstimmende Bild-MIME-Typen
Beispiel: Dateiname ist image1.webp, tatsächlicher Inhalt ist PNG, deklarierte Beziehung ist image/jpeg. Word lehnt die Datei ab.
2. Ungültige Bilddimensionen
Wenn Word auf Null- oder negative Dimensionswerte trifft, wird das Dokument als beschädigt angesehen.
3. Nicht unterstützte Formate
Microsoft Word unterstützt nicht: SVG, WebP oder AVIF. Selbst teilweise Unterstützung oder Fallback-Versuche können die Datei beschädigen.
4. Defekte OpenXML-Beziehungen
Wenn document.xml auf eine Bildbeziehungs-ID verweist, die in document.xml.rels nicht existiert, versagt Word sofort.
Warum HTML-zu-DOCX-Bibliotheken oft scheitern
Die meisten Bibliotheken versuchen, zu viel zu automatisieren.
Typisches Verhalten:
Das funktioniert für einfache Seiten — scheitert aber katastrophal bei:
Das Ergebnis: strukturell ungültige DOCX-Dateien.
Die Ingenieur-Lösung (Die einzige zuverlässige)
Die Lösung ist nicht „saubereres HTML".
Die Lösung ist vollständige OpenXML-Kontrolle über Bilder.
Goldene Regel
Lassen Sie niemals einen HTML-zu-DOCX-Konverter Bilder automatisch verwalten.
Korrekte Web-zu-Word-Architektur
1. HTML einmal abrufen
2. Inhalt bereinigen (SVG, Scripts, Lazy Loading entfernen)
3. Bilder extrahieren
4. Bilder herunterladen
5. Zu JPEG oder PNG neu kodieren
6. Dimensionen validieren
7. Bilder manuell in DOCX einbetten
Bilder müssen sein:
Warum diese Lösung zu 100% funktioniert
Weil Microsoft Word genau das tut, was es verspricht:
Sobald jedes Bild:
Hat Word keinen Grund, eine Warnung über unlesbaren Inhalt anzuzeigen.
Best Practices für SaaS-Konverter
Wenn Sie einen Web-zu-Dokument-Service betreiben:
Nutzer vertrauen Dokumenten, die sauber öffnen, mehr als Dokumenten, die „fast" perfekt aussehen.
Fazit
„Word hat unlesbaren Inhalt gefunden" ist kein Rätsel.
Es ist ein strukturelles Versagen, fast immer verursacht durch unsachgemäß eingebettete Bilder während der Web-zu-DOCX-Konvertierung.
Sobald Sie Word als strikten XML-Validator behandeln, nicht als Browser, wird die Lösung offensichtlich — und dauerhaft.
Abschließende Erkenntnis
Wenn Google Docs Ihre Datei öffnet, aber Word nicht, ist Ihr DOCX nicht konform — es wird nur toleriert.
Beheben Sie die Struktur, und das Problem verschwindet für immer.
Probieren Sie Page2Doc
Konvertieren Sie Webseiten zu Word-Dateien, die tatsächlich öffnen. Keine Beschädigung. Keine Wiederherstellungsaufforderungen.
Page2Doc verwendet OpenXML-sichere Bildverarbeitung, um sicherzustellen, dass jedes Dokument Words strenge Validierung besteht.