Por qué Word muestra 'Contenido ilegible' al convertir páginas web a DOCX
Introducción
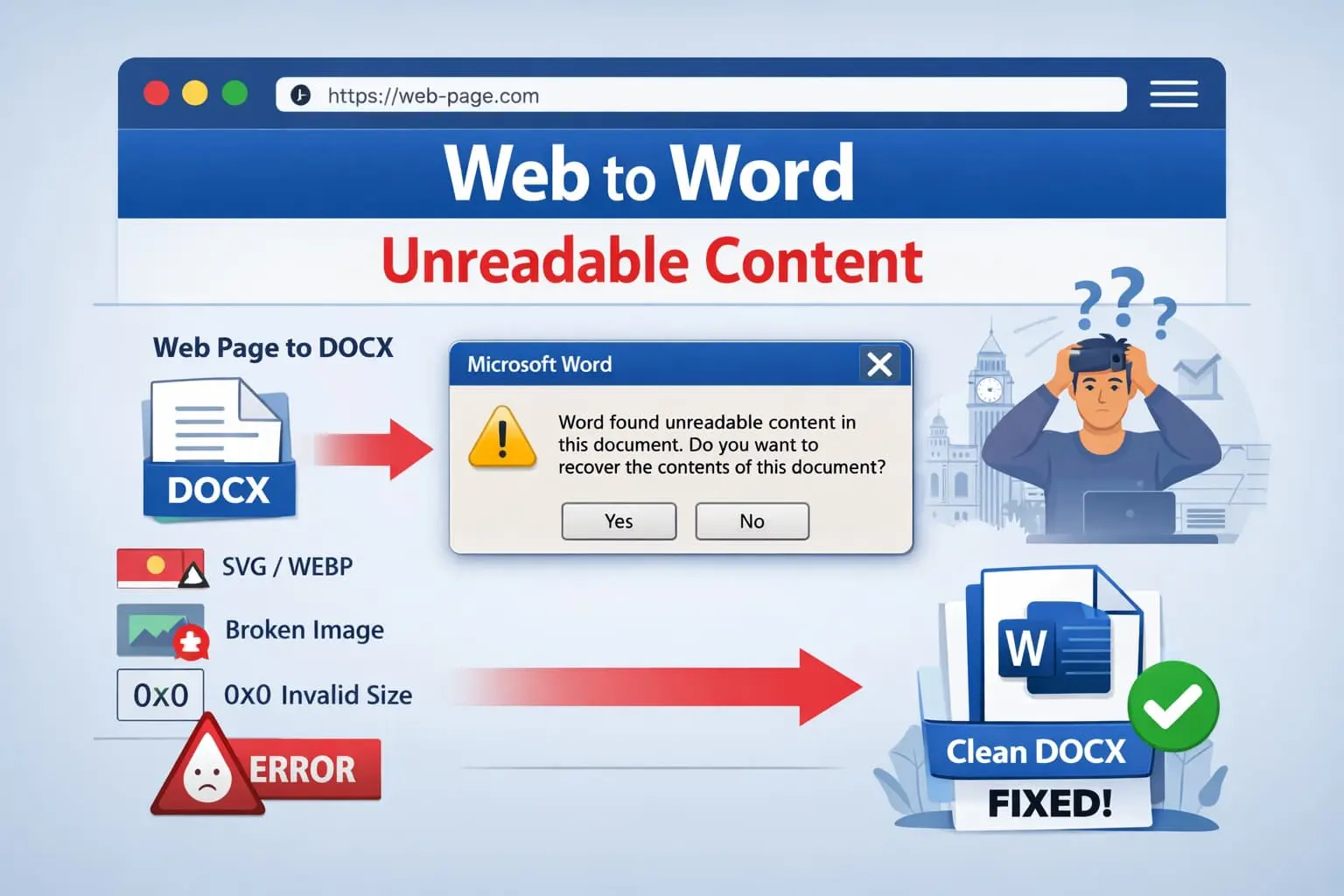
Si alguna vez has convertido una página web a Word y te has encontrado con este mensaje:
"Word encontró contenido ilegible en este documento. ¿Desea recuperar el contenido?"
no estás solo.
Este problema afecta a:
¿La parte frustrante? El documento se ve bien en Google Docs — pero Microsoft Word lo rechaza.
Este artículo explica la verdadera razón técnica detrás de la ilegibilidad de DOCX, por qué la mayoría de los convertidores fallan, y cómo solucionar el problema a nivel de ingeniería, no con parches.
Qué significa realmente "Contenido ilegible" en Word
Microsoft Word no se está quejando de tu texto.
Te está diciendo que la estructura OpenXML del archivo DOCX es inválida.
Un archivo .docx es:
Si un solo elemento viola la especificación, Word marca todo el documento como corrupto.
Por qué la conversión web a Word es especialmente frágil
Las páginas web nunca fueron diseñadas para convertirse en documentos Word.
Contienen:
Word, por otro lado, espera:
Este desajuste es donde todo se rompe.
La causa raíz #1: Imágenes, no texto
En más del 90% de los casos del mundo real, las imágenes son la razón por la que Word reporta contenido ilegible.
Los problemas fatales comunes incluyen:
1. Tipos MIME de imagen no coincidentes
Ejemplo: el nombre del archivo es image1.webp, el contenido real es PNG, la relación declarada es image/jpeg. Word rechaza el archivo.
2. Dimensiones de imagen inválidas
Si Word encuentra valores de dimensión cero o negativos, el documento se considera corrupto.
3. Formatos no soportados
Microsoft Word no soporta: SVG, WebP o AVIF. Incluso el soporte parcial o los intentos de respaldo pueden corromper el archivo.
4. Relaciones OpenXML rotas
Si document.xml referencia un ID de relación de imagen que no existe en document.xml.rels, Word falla inmediatamente.
Por qué las bibliotecas HTML a DOCX a menudo fallan
La mayoría de las bibliotecas intentan automatizar demasiado.
Comportamiento típico:
Esto funciona para páginas simples — pero falla catastróficamente para:
El resultado: archivos DOCX estructuralmente inválidos.
La solución de nivel ingeniería (La única confiable)
La solución no es "HTML más limpio".
La solución es control total de OpenXML sobre las imágenes.
Regla de oro
Nunca dejes que un convertidor HTML a DOCX gestione las imágenes automáticamente.
Arquitectura correcta de web a Word
1. Obtener HTML una vez
2. Sanitizar contenido (eliminar SVG, scripts, carga diferida)
3. Extraer imágenes
4. Descargar imágenes
5. Re-codificar a JPEG o PNG
6. Validar dimensiones
7. Incrustar manualmente imágenes en DOCX
Las imágenes deben ser:
Por qué esta solución funciona el 100% de las veces
Porque Microsoft Word hace exactamente lo que promete:
Una vez que cada imagen:
Word no tiene razón para mostrar una advertencia de contenido ilegible.
Mejores prácticas para convertidores SaaS
Si ejecutas un servicio web a documento:
Los usuarios confían en documentos que se abren limpiamente más que en documentos que "casi" se ven perfectos.
Conclusión
"Word encontró contenido ilegible" no es un misterio.
Es una falla estructural, casi siempre causada por imágenes incorrectamente incrustadas durante la conversión web a DOCX.
Una vez que tratas a Word como un validador XML estricto, no como un navegador, la solución se vuelve obvia — y permanente.
Conclusión final
Si Google Docs abre tu archivo pero Word no, tu DOCX no es compatible — simplemente es tolerado.
Arregla la estructura, y el problema desaparece para siempre.
Prueba Page2Doc
Convierte páginas web a archivos Word que realmente se abren. Sin corrupción. Sin avisos de recuperación.
Page2Doc usa manejo de imágenes seguro para OpenXML para asegurar que cada documento pase la validación estricta de Word.