Pourquoi Word affiche « Contenu illisible » lors de la conversion de pages web en DOCX
Introduction
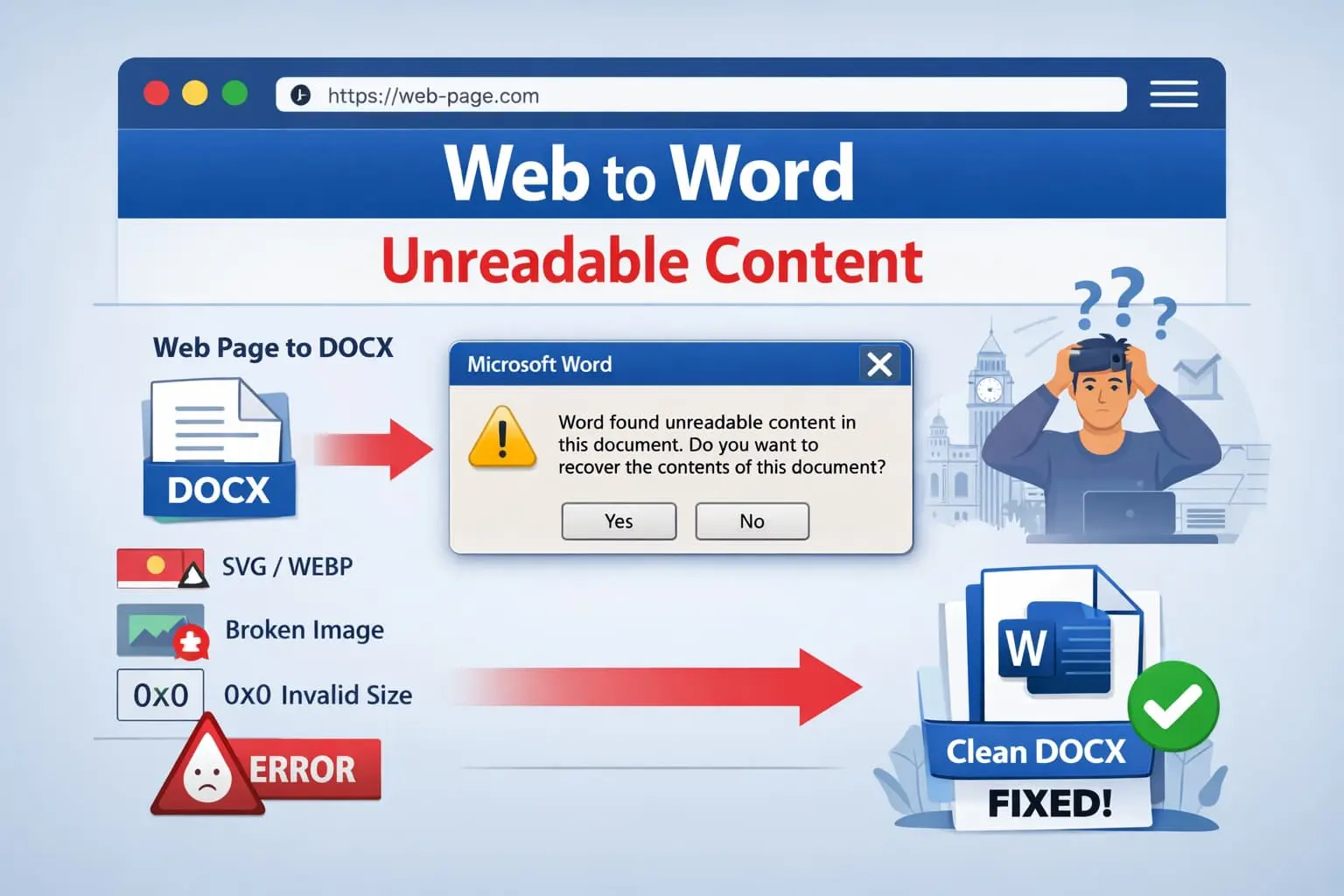
Si vous avez déjà converti une page web en Word et été accueilli par ce message :
« Word a trouvé du contenu illisible dans ce document. Voulez-vous récupérer le contenu ? »
vous n'êtes pas seul.
Ce problème affecte :
La partie frustrante ? Le document s'ouvre bien dans Google Docs — pourtant Microsoft Word le refuse.
Cet article explique la véritable raison technique derrière l'illisibilité des DOCX, pourquoi la plupart des convertisseurs échouent, et comment résoudre le problème à un niveau d'ingénierie, pas avec des solutions de fortune.
Ce que signifie réellement « Contenu illisible » dans Word
Microsoft Word ne se plaint pas de votre texte.
Il vous dit que la structure OpenXML du fichier DOCX est invalide.
Un fichier .docx est :
Si un seul élément viole la spécification, Word signale l'ensemble du document comme corrompu.
Pourquoi la conversion web vers Word est particulièrement fragile
Les pages web n'ont jamais été conçues pour devenir des documents Word.
Elles contiennent :
Word, en revanche, s'attend à :
Cette incompatibilité est là où tout se casse.
La cause n°1 : les images, pas le texte
Dans plus de 90% des cas réels, les images sont la raison pour laquelle Word signale un contenu illisible.
Les problèmes fatals courants incluent :
1. Types MIME d'image non concordants
Exemple : le nom du fichier est image1.webp, le contenu réel est PNG, la relation déclarée est image/jpeg. Word rejette le fichier.
2. Dimensions d'image invalides
Si Word rencontre des valeurs de dimension nulles ou négatives, le document est considéré comme corrompu.
3. Formats non supportés
Microsoft Word ne supporte pas : SVG, WebP ou AVIF. Même un support partiel ou des tentatives de fallback peuvent corrompre le fichier.
4. Relations OpenXML cassées
Si document.xml référence un ID de relation d'image qui n'existe pas dans document.xml.rels, Word échoue immédiatement.
Pourquoi les bibliothèques HTML-vers-DOCX échouent souvent
La plupart des bibliothèques essaient d'automatiser trop de choses.
Comportement typique :
Cela fonctionne pour les pages simples — mais échoue de manière catastrophique pour :
Le résultat : des fichiers DOCX structurellement invalides.
La correction de niveau ingénierie (la seule fiable)
La solution n'est pas un « HTML plus propre ».
La solution est un contrôle OpenXML complet sur les images.
Règle d'or
Ne laissez jamais un convertisseur HTML-vers-DOCX gérer les images automatiquement.
Architecture correcte web-vers-Word
1. Récupérer le HTML une fois
2. Nettoyer le contenu (supprimer SVG, scripts, chargement différé)
3. Extraire les images
4. Télécharger les images
5. Ré-encoder en JPEG ou PNG
6. Valider les dimensions
7. Intégrer manuellement les images dans le DOCX
Les images doivent être :
Pourquoi cette correction fonctionne 100% du temps
Parce que Microsoft Word fait exactement ce qu'il promet :
Une fois que chaque image :
Word n'a aucune raison d'afficher un avertissement de contenu illisible.
Meilleures pratiques pour les convertisseurs SaaS
Si vous gérez un service web-vers-document :
Les utilisateurs font davantage confiance aux documents qui s'ouvrent proprement qu'aux documents qui sont « presque » parfaits.
Conclusion
« Word a trouvé du contenu illisible » n'est pas un mystère.
C'est une défaillance structurelle, presque toujours causée par des images incorrectement intégrées lors de la conversion web-vers-DOCX.
Une fois que vous traitez Word comme un validateur XML strict, et non comme un navigateur, la correction devient évidente — et permanente.
Point clé final
Si Google Docs ouvre votre fichier mais pas Word, votre DOCX n'est pas conforme — il est simplement toléré.
Corrigez la structure, et le problème disparaît pour toujours.
Essayez Page2Doc
Convertissez des pages web en fichiers Word qui s'ouvrent réellement. Pas de corruption. Pas de messages de récupération.
Page2Doc utilise une gestion d'images sécurisée OpenXML pour garantir que chaque document passe la validation stricte de Word.